
バイブコーディングで論文は書けるか
2025年の最大のブレイクスルーは、エージェントAIの登場だった。藤井聡太名人が「バイブコーディング」を実践していると報じられたのは、つい先日の話だ。棋士というコーディングには一見無縁の方であっても「便利ツール」を時前で生成する時代が到来したことを象徴するエピソードだろう。
こうなってくると、研究者としては自然に浮かぶ疑問がある。エージェントAIで論文は書けるのか。
もちろん、これまでもAIを使って文章を生成することはできた。アウトラインを渡せば、それなりの文章が返ってくる。けれど僕がここで問うているのは、もっと構造的な営みだ。複数の参考文献を整理し、既存研究の限界を指摘し、独自の視点を提示する。この一連のプロセスを、果たしてAIに委ねることができるのか。
実は、その答えはすでに出ている。少なくとも僕の場合、今年の夏、1ヶ月で合計5万字の論文ドラフトを執筆したのだ。
ソフトウェア開発の世界では、「仕様駆動型開発(SDD)」という考え方がある。それになぞらえれば、参考文献はライブラリ、全体構想は仕様書、ドラフト生成はコード生成というわけで、その考え方は驚くほど共通している。ただし、完全に同じではない。なぜなら、論文執筆では「仕様」自体も執筆プロセスを通じて発見されていくからだ。今回は、その執筆フローについて説明したい。
一貫性を保持する「構造化された規則」
従来のAI執筆アプローチは、単純だった。アウトラインを渡し、「これに沿って文章を書いて」と指示する。それで数百字から数千字の文章は生成できる。しかし、数万字の論文を一貫性を持って執筆させようとすると、すぐに限界が見えてくる。
章ごとに論調が変わる。同じ概念を別の言葉で説明し始める。前の章で述べたはずの議論を、また繰り返す。AIには、論文を構成する上で参照点となる長期記憶がないのだ。
エージェントAIが可能にするのは、この一貫性の維持だ。複数の資料を参照し、一定の執筆ルールに基づき、構造に沿って文章を生成する。これによって「情報の整理」から「既存の研究に基づく限界の指摘」「筆者独自の視点の提示」までを、生成AIに任せるフローができる。
その一貫性を維持するための解決策となるコンセプトが「構造化された規則」だ。
ソフトウェア開発では、プロジェクト構造が重要視される。どのディレクトリに何を置くか、ファイルをどう命名するか。これらは単なる整理術ではなく、設計思想そのものなのだ。論文執筆も同じである。
ディレクトリ構造という「設計図」を作る。プロジェクトルートには、全体に関わる指示や資料を置く。各章ディレクトリには、章ごとの設計図、作業記録、成果物を配置する。ファイル命名規則を統一し、バージョン管理と作業段階を可視化する。
この構造こそが、AIに一貫性を持たせるための骨格になる。構造化された規則があれば、AIは迷子にならない。むしろ、構造に沿って思考を展開していくのだ。
執筆フローの5つの段階
実際に僕が実践した執筆プロセスは、5つの段階に分けられる。
1. 文献整理
まず、章で使う資料の情報を構造化して保存する。公開論文であれば、NotebookLMなどのツールで要約を作成することもできる。この段階で複数の論文を要約させ、そこで扱われていない論点を抽出することも可能だ。つまり、文献レビューの段階で、すでに「ギャップ分析」が始まっているのである。
2. アウトライン作成
構想ファイルと資料をもとに、章の設計図を作成する。特に構想を固めていく段階では、前回述べた「壁打ち」としてのAI利用が極めて有効だ。対話型プロンプトを用いて、AIと議論を重ねながら論点を整理していくのである。
重要なのは、ときにAIの提案を拒否することだ。AIは往々にして、大規模サーベイや実験計画など、ハードルの高い研究を提案してくる。そこで僕は、「身の丈に合ったアプローチ」に整理していくことを心がけた。自分のリソースで実現可能な範囲に、問いを絞り込むのである。これは、前回の記事で挙げた「6つの目的」で言えば、「不明点の明確化」と「目標設定」に相当する作業だ。
3. ドラフト生成
次は設計図に基づいて本文を生成する段階だ。今回は一回の指示で、おおむね数千字単位の内容を生成させた。そのため、章・節の構成や趣旨などに一貫性を持たせるための指示が必要になる。
ポイントは、生成したドラフトから章の構成を変更することもある、という点だ。つまり、ドラフトを読んで「この流れの方が良いのではないか」と気づくことがある。これは、執筆が思考を進化させる典型例だ。
4. AI査読
生成されたドラフトを、AIに批判的に読ませる。これは、従来の「生成」とは逆方向のAI利用だ。論理の飛躍はないか、引用は適切か、議論に穴はないか。AIに、厳しい査読者の役割を演じさせるのである。
5. 修正
査読結果をもとに、原稿を改善する。この段階は、人間の判断が最も重要になる。AIの指摘をすべて採用するわけではない。むしろ、AIの指摘を参考にしながら、著者としての主張を明確にしていくのだ。
これらの5つの段階は、ソフトウェア開発における「設計→実装→テスト→デバッグ」のサイクルに似ている。ただし、論文執筆には「仕様の発見」という独自のプロセスが含まれる。書きながら、何を書くべきかが明確になっていくのである。
なお、これは「2025年夏時点での方法」であることを強調しておきたい。AIの能力は日々進化しており、このフロー自体も常にアップデートされている。さらに今回生成した論文は未刊行であり、このあとも改稿作業が続くので、「一発で完成品を生成」というわけではない。内容面での学術的な意義や価値は、今後の評価に委ねられることになる。
CONTEXT.mdという「仕様書」
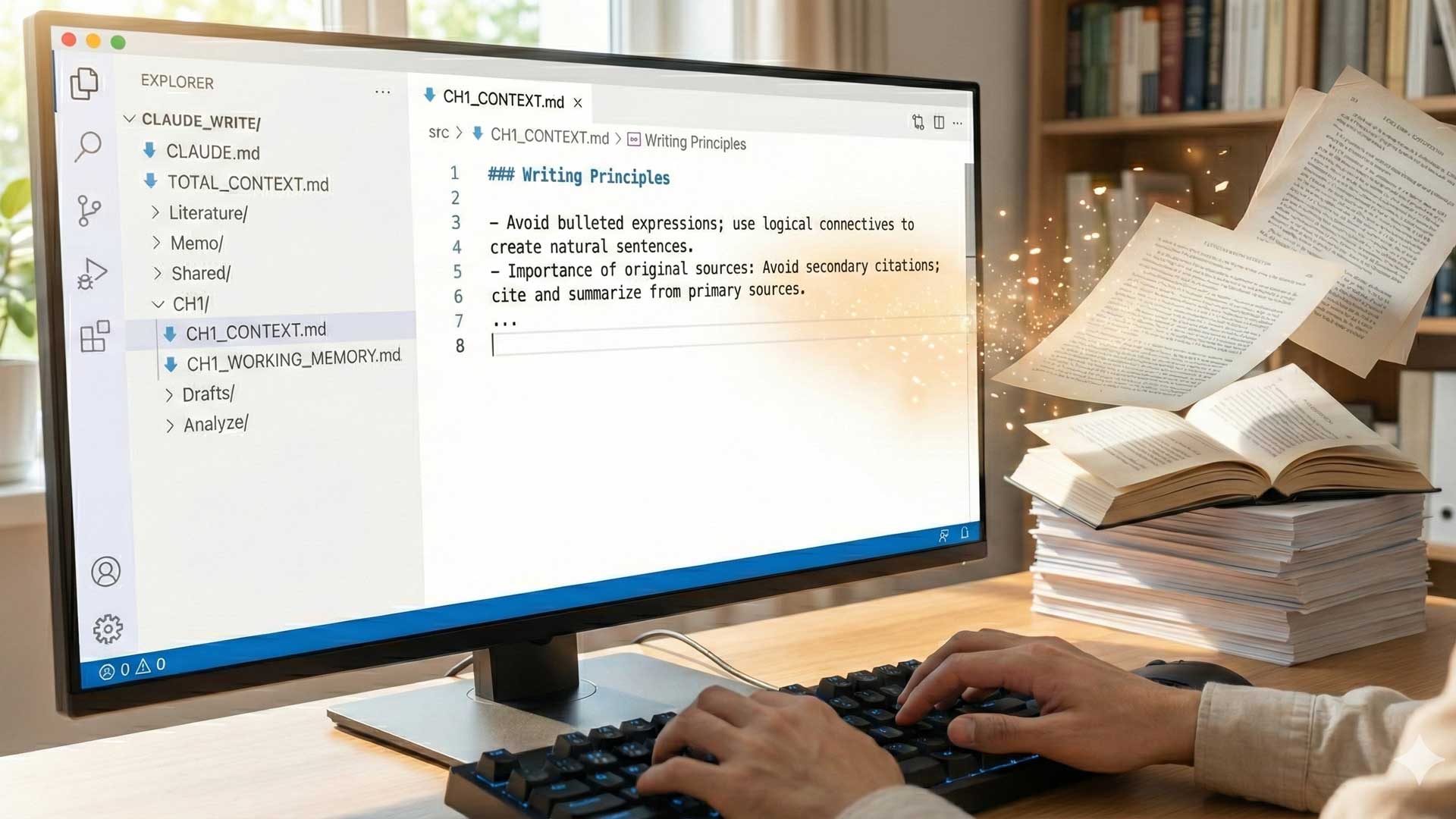
さて、気になるのは、具体的にどのような指示を与えればよいのかということだろう。使用したのはVS CodeのプラグインとしてのClaude Code。ここでは、VS Codeのプロジェクトを作成し、そのルートに配置したCONTEXT.mdを「仕様書」として扱い、以下のような構造でAIに指示を渡した。
まず、論文執筆プロジェクトのディレクトリ構造は次のようになっている。
CLAUDE_WRITE/ # プロジェクトルート
├── CLAUDE.md # 標準手順書(変わらないルール)
├── TOTAL_CONTEXT.md # 論文全体の構成と主張
├── Literature/ # 参考文献の元データと要約(PDF/MD)
├── Memo/ # アイデア・AIとの対話ログ
├── Shared/ # 章横断で使う図版・表など
└── CHx/ # 第x章ディレクトリ
├── CHx_CONTEXT.md # 第x章の設計図
├── CHx_WORKING_MEMORY.md # 作業記録
├── Drafts/ # ドラフト保存先
│ ├── CHx_s1_draft_v1.md
│ ├── CHx_s1_draft_v2.md
│ └── CHx_s1_draft_v2_after_review.md
└── Analyze/ # アウトライン・査読結果
├── CHx_s1_outline_v1.md
└── CHx_s1_ai_review_v1.mdこの構造を眺めると、いくつかの原則が見えてくる。
まず、CLAUDE.md(標準手順書)には、執筆の基本手順、ファイル命名規則、セッション開始・終了時の手順などを記載している。例えば「セッション開始時に必ず読み込むファイル」や「執筆原則(箇条書き的表現を避ける、原典重視など)」といった内容だ。これは、プロジェクト全体で変わらないルールである。
次に、TOTAL_CONTEXT.md(全体構想)には、論文全体の構成、各章の位置づけ、著者の主たる主張を記述している。例えば「第1章は理論史整理、第2章は欧米の事例の検討、第3章は理論的定式化」といった形だ。これは、章をまたいだ論理的一貫性を維持するための羅針盤になる。
そして、CHx_CONTEXT.md(章ごとの設計図)には、その章の目標、論理構成、基幹文献、特殊なルールを記載する。実際の指示の例を示そう。
### 執筆原則
- 箇条書き的表現は避け、論理接続詞を用いて自然な文章にする
- 原典重視:孫引きを避け、一次資料から引用・要約する
- 著者の見解と先行研究を明確に区別する
### 第2節の構成と著者見解の配置
1. 先行研究レビュー (60%): 複数の文献を体系的に整理
2. 著者の理論的統合 (40%): 独自の概念の提示この程度の粒度が、ちょうど良いバランスだと僕は考えている。「各段落は3-5文で構成する」といった細かすぎる指示は、柔軟性を失う。逆に「学術的に書く」といった抽象的すぎる指示は、解釈の幅が広すぎる。「箇条書き的表現を避け、論理接続詞を用いて自然な文章にする」という程度の粒度が、AIに適切な自由度を与えつつ、方向性を示すことができる。
最後に、CHx_WORKING_MEMORY.md(作業記録)には、前回の作業内容、次回への引き継ぎ、発見した理論的課題を記録する。例えば「今回は第1節のドラフト生成まで完了。次回はAI査読から開始」といった形だ。AIは前回のセッションを記憶していないため、この作業記録が連続性を保つ鍵になる。
指示が衝突した場合の優先順位も、明確にしておく必要がある。これについては次のような階層にした。
- CHx_CONTEXT.mdの特殊ルール(章ごとの固有の要件)
- CLAUDE.md(全体の標準手順)
- CHx_WORKING_MEMORY.md(進捗ログのみ、構造は記載しない)
「毎回同じ指示を与える」ことも重要だ。セッション開始時に必ず読み込むファイルを明示する。例えば「CLAUDE.md, TOTAL_CONTEXT.md, CHx_CONTEXT.md, CHx_WORKING_MEMORY.mdを読み込む」といった形だ。AIは前回のことを記憶していないため、「再現性」が鍵になる。毎回同じファイルを読み込ませることで、一貫した出力を得られるのだ。
しかし、これは完璧な方法ではない。実際、執筆中に何度もCLAUDE.mdを書き直したし、書き直した指示に合わせて生成したドラフトを修正する必要も生じた。
ここに、ソフトウェア開発との大きな違いがある。ソフトウェア開発では、仕様変更は原則避けるべきだとされる。しかし、論文執筆では、書きながら「何を書くべきか」が明確になる。つまり、論文執筆は「仕様の発見プロセス」なのだ。この違いは重要である。書くことで、思考が進化していく。
執筆の1ヶ月で起きたこと
では、実際に何が起きたのか。時間の内訳から見ていこう。
前半の2週間は、構造設計とルール策定に費やされた。どのようにコンテキストを整理してAIに渡すかを試行錯誤を続け、ファイル命名規則を何度も変更し、CLAUDE.mdの執筆原則を書き直し、ディレクトリ構造を再編した。この段階では、まだドラフトはほとんど生成していない。生成した結果からベストプラクティスを整理させ、CLAUDE.mdに反映させる作業が大半の時間を占めた。
後半の3週間で、実際の執筆を行った。ただし、この3週間の大半は、先行研究の整理とアウトラインの指示作成に費やされた。執筆といってもドラフト生成自体は数分で完了する。時間がかかるのは、そのための前処理なのだ。
何がうまくいったか。まず、一貫性の維持だ。章や節をまたいでも文体や概念、結論として言いたいことに向けた論理展開が維持される。TOTAL_CONTEXT.mdが、論文全体の羅針盤として機能したのだ。
次に査読サイクル。AIに批判させることで、明らかに文章の質が向上した。当初段階ではどこか「AIっぽい」文章だったものが、比較的読めるものになった。AIの査読結果に僕から見た問題点や限界を書き加えることで、修正の方向性をコントロールすることもできた。
最後に驚いたのがセレンディピティの発生だ。これは予想外だった。指示通りであるはずなのに、生成した文章が思わぬ着想につながる。ドラフトを読んで「ああ、この論点もあったのか」と気づくことがあった。これは、書くことで思考が進化する典型例だ。AIは、僕の思考を外部化し、新しい視点を提供してくれたのである。
逆にうまくいかなかったものもある。まず、参考文献の読み込みがコンテクストを圧迫した。PDFファイルをそのまま読み込ませると、すぐにトークン数の上限に達してしまう。そこでNotebookLMで要約を作成し、その要約をAIに渡すという方法に切り替え、文献レビューの処理を外部化した。
次に、指示が曖昧だとAIの出力も意図したものにならなかった。学術的にもっともらしい記述になるのだが、前の文脈とつながらなかったり、意図とは違う結論を出力したりしてきたのだ。これは当然だと思うけれど、どの程度の粒度で指示すればよいのかは、実際に試してみないとわからない。結果として、CLAUDE.mdは執筆中に何度も書き直された。
また、統計データの処理やインタビューデータなどの質的情報の処理は未着手だ。今回の5万字は、理論研究だったからこそできたケースである。ただし、秋の学会発表でも先行研究の整理に関しては同じ仕組みで成功している。部分的な汎用性は確認できたと言えるだろう。
というわけで、これは「完璧なフロー」ではなく、「ある時点では機能したフロー」なのだ。なので今回の記事でも「このようなCLAUDE.mdを用意すれば誰でも論文が書ける」というようなハウツー的な話はしていない。
研究の価値はどこへ向かうのか
さて、こうした新しい執筆スタイルは、学術研究にどのような影響を及ぼすだろうか。今回の論文生成で苦労したような論点はより洗練されたノウハウになるだろう。論文生成が合理的なプロセスになれば、研究業績としての論文数は価値指標にならなくなると思う。研究者の評価は、これまで「何本書いたか」で測られてきた。しかし、その前提が崩れつつあるということだ。
では、「研究」の価値はどこで判断されるようになるのか。僕は、「量より質」への転換が起きると考えている。研究の価値は、「問いの設定」「資料の選択」「理論的統合」にシフトするのである。現在のAIは、オリジナルな問題意識、批判的な文献読解、独自の理論的視点といったものをまだ生成できない。これらは、引き続き人間の手になる領域なのだ。
さらには「構造を設計する力」も重要になる。AIに何をどう指示するかは、結局のところ人間の仕事だ。仕様書を書く力が、研究者の新しいスキルになるのかもしれない。
では、そうやって「AIで書いた」論文に価値はあるのか。
これについては今後もアカデミアの間で大論争になるだろう。とりわけ人文系の学問ではその論争は激しいものになるかもしれない。でも僕はそもそも、その問い自体が誤りだと思う。
なぜなら、執筆の自動化によって、思考に使える時間が増えたことこそが本質的な変化だからだ。「書く」作業から解放されることで、「考える」作業に集中できる。文献を読み込み、論点を整理し、問いを洗練させる。これらの知的営為に、より多くの時間を割けるようになったのだ。
AIは論文を書くが、研究はしない。問いを立てるのは人間であり、資料を選ぶのも人間であり、理論的統合を行うのも人間である。AIは、その営みを加速するツールにすぎない。
エージェントAIは、「思考の外部化」を加速する。書くことで思考が進化する、という営みを、より効率的に行えるようにする。そのための構造が、ディレクトリであり、CONTEXT.mdであり、執筆フローなのだ。
次回は、このフローをさらに発展させた「タスク管理と情報管理の統合」について考えてみたい。